[NLP] Extracting Information from Text : Information Extraction
7. Extracting Information from Text
www.nltk.org
우리가 무언가에 대해 궁금해 하고, 질문에 대한 해답을 찾으려고 하면 이는 이미 답변이 존재하는 경우가 많다. 매일매일 수 천, 수 만 개의 자연어 텍스트가 증가하고 있으나 자연어의 복잡성은 그 텍스트의 정보에 접근하는 것을 어렵게 만들 수 있다. 이번 단원의 목표는 아래 세 질문에 대한 답을 찾는 것이다.
| 1. 구조화되지 않은 텍스트에서 구조화된 데이터 (예 : 표)를 추출하는 시스템을 구축할 수 있을까? 2. 텍스트에 설명된 객체(데이터 집합 ; Entity)와 관계(relationship)를 식별할 수 있는 강력한 방법은 무엇인가? 3. 어떤 말뭉치(corpus)가 이 작업에 적합하며, 모델을 훈련시키고 평가하는데에 어떻게 사용할 수 있을까? |
1. Information Extraction
정보는 다양한 형태로 제공된다. 그 중 구조화된 데이터(Structured Data)는 객체(Entity)와 관계의 규칙적이고 예측 가능한 조직을 가진다. 예를 들어, 회사와 위치 간의 관계가 존재한다고 하자. 이 경우 특정 기업이 영업을 하는 위치를 알 수도, 혹은 특정 위치에서 일 하는 회사의 종류를 파악할 수도 있다.

기업의 이름과 위치 간의 관계를 나타낸 자료가 있다. 위 자료에서 "New York에서 운영되는 조직은 무엇인가요?"라는 질문을 한다면 다음과 같이 도출해낼 수 있다.
locs = [('Omnicom', 'IN', 'New York'),
('DDB Needham', 'IN', 'New York'),
('Kaplan Thaler Group', 'IN', 'New York'),
('BBDO South', 'IN', 'Atlanta'),
('Georgia-Pacific', 'IN', 'Atlanta')]
query = [e1 for (e1, rel, e2) in locs if e2=='New York']
print(query)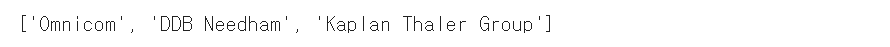
그러나 만약 "그 에이전시는 Georgia-Pacific의 종이 제품을 취급하는 부서로, 작년 가을에야 기관 이전을 완료했습니다. BBDO World Wide의 BBDO South 유닛으로 병합된 것입니다. BBDO South는 Atlanta의 기업 광고를 취급하는 유닛으로 지면 광고를 다루기 위해 추가 인원을 다른 회사로부터 지원받은 것으로 나타났습니다." 같은 글이 있다면 어떨까? 글을 끝까지 읽어본다면 BBDO South가 Atlanta를 기점으로 작업한다는 사실을 알 수는 있지만 기계가 그 내용을 도출해내기까지는 꽤나 시간이 걸리는 어려운 일일 것이다.
이런 문제에 대해 해결하기 위한 방법으로는 매우 일반적인 의미 표현을 구축하는 것이 있다.
1-1. Information Extraction Architecture
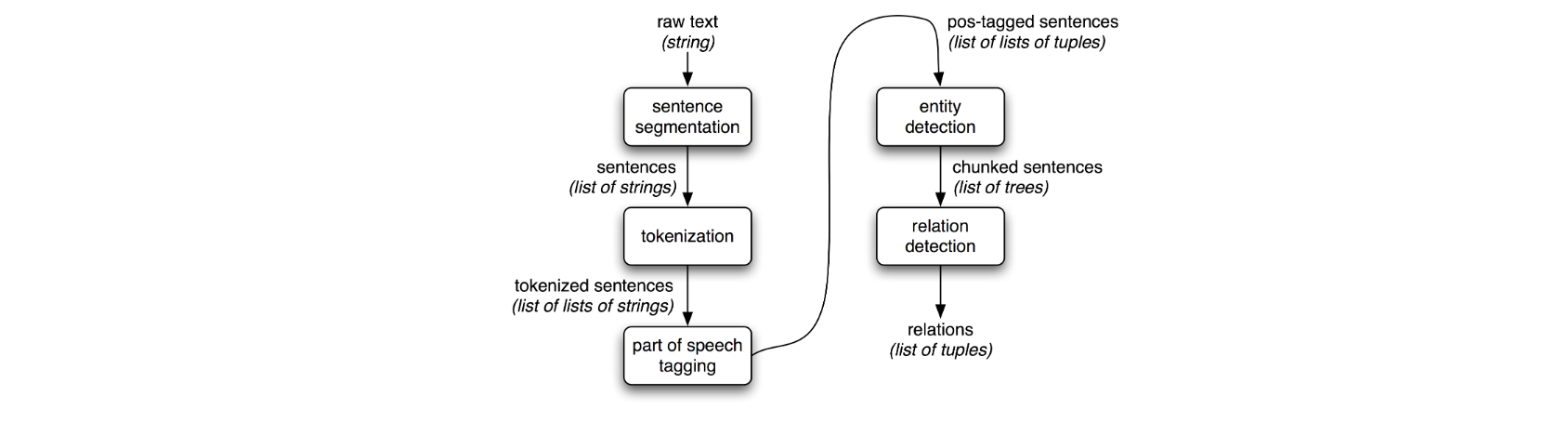
위 그림은 단순 정보 추출 시스템의 구성을 보여준다. (1) 문서의 원시 텍스트를 문장 단위로 나누고 (2) 각 문장을 토큰화하여 더 세분화한다. (3) 그 다음, 각 문장에 POS 태깅을 거치고 (4) 객체 탐지와 (5) 관계 탐지를 통해 정보를 추출해내는 방식이다. 첫 세 과정은 아래와 같은 함수를 사용해 진행할 수 있다.
def ie_preprocess(document):
sentences = nltk.sent_tokenize(document) [1]
sentences = [nltk.word_tokenize(sent) for sent in sentences] [2]
sentences = [nltk.pos_tag(sent) for sent in sentences] [3]
다음으로, 객체를 분할하고 레이블을 지정한다. 일반적으로 이는 확실한 명사구나 고유명사가 된다. (모두 그런 것은 X) 이후 마지막으로, 특정 패턴을 검색하고, 이를 이용해 객체 간의 관계를 기록하는 튜플을 구축한다.